Backups are critically important, but often ignored. Their true value only becomes obvious when you need one but don’t have one. I’ve myself been negligent on a few occasions and have lost some data.
For data that you consider vital such as personal family photos or baby videos, the easiest solution is to use a cloud provider. Based on your ecosystem this could be Google, Amazon, Dropbox, Apple or a myriad of any others out there.
My focus here however is on rolling out my own system. A good backup strategy has multiple layers, I’m going to outline my strategy here, but before that let’s first review some of the things that we want to achieve with our system.
- Reliable, we should be able to retrieve data when we need it
- Current, the backup should be reasonably current. It may be Ok to lose data from the last few hours or a couple of days, but not for months.
- Cheap, the system shouldn’t cost an arm and a leg.
Whenever we’re building any system, there are trade-offs and our homebrew backup system is no different. My preference is towards having a reliable and cheap system and I’m willing to sacrifice the ability of having access to my most recent work.
I don’t make this trade-off decision lightly, but given my workflow, all the code that I’m working on is committed nightly if not sooner to a personal branch on the Git Remote. My architectural diagrams and wiki contributions are online, interpersonal communication is over email and Slack and that data is automatically backed up.
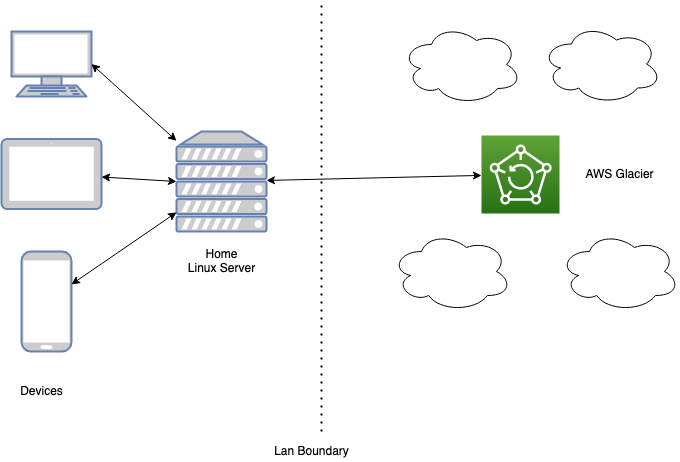
The main components of this system are the home server that I run on my own network. The hardware is an i5 intel NUC board with a SSD and 16 GB of Ram, this server does a few more things other than just backups. I have 3 external hard drives attached (totalling 7 TB of storage space) for providing me network storage and obviously for backups. This also runs a timemachine server to backup my macs to.
The home server is the first line of defense, should one of my devices go down I can easily restore from a daily backup on the home server.
The more interesting question is what happens if my server gets fried or more specifically what happens if a hard drive on my server fails. To cover for that case, I’ve chosen AWS Glacier as the backing store. While S3 is the most ubiquitous object storage solution, it’s quite expensive to back up data to due to the high per GB storage costs. Glacier is a service that’s designed primalily for backing up and archiving data. You can’t download an archive immediately, first you need to fire of a retrieval job which might take a day or so to have the data available for download and then you can download your data.
Let’s look at the pricing numbers, please note that these numbers may not be accurate when you read this because AWS keeps chainging their prices (mostly lowering them, but who knoww what the future may hold).
The storage pricing in Oregon is currently $0.004 per GB / Month, the retrieval pricing depends on how fast you need access to your data, I’ve picked the Standard price for calculation which is $0.01 per GB. There’s an additional price for requesting a retrieval, but for a home backup system that’s likely negligible and hence I’m ignoring that here.
Let’s also assume that we’re storing 1 TB of data, the monthly cost to store this would be 0.004 * 1024 = $4.096 per month and when our system fails it would cost $10.24 to retreive this data. The annual cost, comes out to $4.096 * 12 + $10.24 = $59.392 or roughly $60. Compared to the similar cloud storage space, this is an absolute bargain. You can ofcourse be much more judicious and selective in backing up what you need to run this system for a fraction of this cost.